
https://www.gitcc.com/iflytek/deep-gpu-plat
企业算力管理平台开源,企业算力集群管理平台开源,企业算力与大模型管理平台
![图片[1]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260601184407174.png)
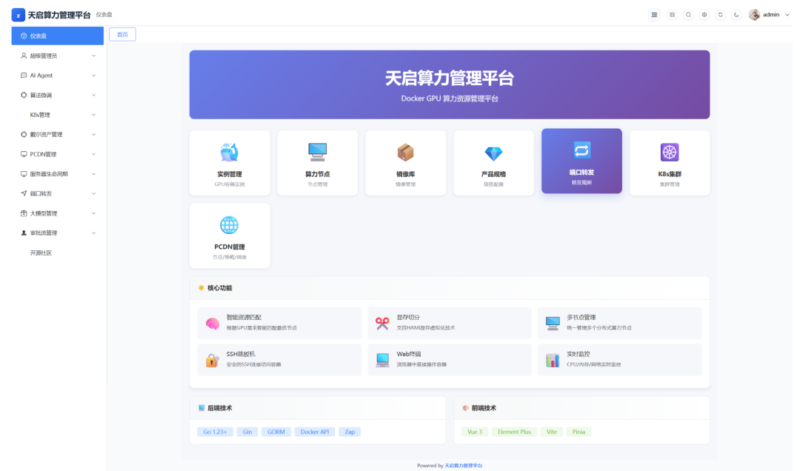
面向企业与团队,提供 GPU 算力、Docker 容器实例与 Kubernetes 集群的统一纳管、调度与运维能力,并集成 AI 辅助、模型微调等扩展能力,降低算力资源使用与运维门槛。
📂 项目概览
- 项目名称:Deep-GPU 算力调度平台
- 开源状态:全面开源
- 适用对象:企业、科研团队、AI基础设施工程师
- 核心价值:将昂贵的算力资源转化为可被普通人调度的生产力。
🌟 核心功能:不止是调度,更是智能管家
Deep-GPU 平台的设计理念非常明确:降低门槛,释放算力。它不仅仅是一个简单的资源分配器,而是一个集成了AI辅助能力的企业级算力中枢。
1. 统一纳管,打破资源孤岛
在传统的IT架构中,GPU资源往往分散在不同的服务器或集群中,难以统一调配。Deep-GPU 提供了强大的统一纳管能力:
- GPU 算力管理:支持主流GPU型号的接入与状态监控。
- 容器化编排:深度集成 Docker 容器实例与 Kubernetes (K8s) 集群,实现了从底层硬件到上层应用的全栈可视化管理。
2. 智能调度,榨干每一分算力
该平台的核心算法能够根据任务的优先级、资源占用情况,进行毫秒级的智能调度,确保高优先级任务(如大模型训练)优先获得资源,而低优先级任务(如推理服务)也能在闲时高效运行。
3. AI 辅助与大模型集成(2026年新特性)
这是该平台区别于传统K8s管理工具的最大亮点。它原生集成了:
- AI 辅助运维:利用AI自动诊断集群故障,预测资源瓶颈。
- 模型微调支持:直接在平台上进行大模型的微调(Fine-tuning)与部署,无需在复杂的命令行中反复横跳。
核心价值
-
统一入口管理 Docker GPU 实例与 K8s 工作负载,降低协作成本。 -
RBAC、操作审计、跳板机与 Web 终端等能力支撑安全合规运维。 -
插件化扩展(AI 对话与配置、微调任务、资产与端口转发等)便于按需启用。
🛠️ 技术架构:企业级的坚实底座
Deep-GPU 的架构设计遵循了云原生的最佳实践,旨在为企业构建一个稳固的AI底座。
表格
| 模块 | 技术栈/能力 | 核心作用 |
|---|---|---|
| 资源层 | GPU 驱动, CUDA | 提供物理算力基础 |
| 编排层 | Kubernetes, Docker | 实现容器的自动化部署与扩缩容 |
| 调度层 | Deep-GPU Scheduler | 智能分配任务,实现算力切片与共享 |
| 应用层 | AI Assistant, LLM Ops | 支持大模型训练、微调与推理服务 |
![图片[2]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260601184409438.png)
https://www.gitcc.com/iflytek/deep-gpu-plat
企业算力管理平台开源,企业算力集群管理平台开源,企业算力与大模型管理平台
© 版权声明
文章版权归作者所有,未经允许请勿转载。
THE END









暂无评论内容