
开源 GCC GPU-Monitor !完全开源!
全流程实时监控的开源工具,支持对训练状态、GPU资源占用、训练日志、IP访问记录
这是个训练炼丹全流程监控系统,GPU 资源一眼看穿!
GCC GPU-Monitor这套开源训练监控系统,把训练状态、GPU 利用率/显存、训练日志、公告通知、IP 访问统计等关键指标做成实时看板,让“炼丹”从玄学变成可观测、可追踪、可复盘的工程流程。
源代码:
https://www.gitcc.com/qiyeapi/gcc-gpu-monitor
![图片[1]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143851593.png)
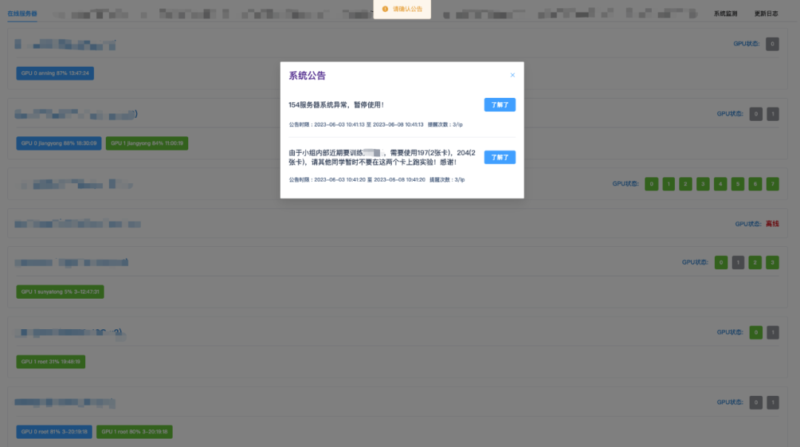
1. 训练进度可视化:闲适炼丹不再“盲跑”
通过“闲适炼丹”模块把训练阶段、进度条、关键节点放到页面实时刷新,团队成员不必反复 SSH 上机器 `tail -f`,也不需要在群里问“现在跑到哪了”。当你同时跑多组实验时,这种统一视图能显著降低沟通成本,避免训练被误停/误改。
2. GPU 资源快览:谁在吃卡、吃多少,一屏看清
实时预览多张 GPU 的利用率、显存占用等核心指标,并支持排序筛选,适合多用户共享服务器/小型集群场景做资源治理。你可以快速定位“显存满但算力低”的异常进程,结合任务信息做负载迁移与排队策略,资源利用率更稳定。
3. 一键式部署与快速接入:把“加一台服务器”变成一行
配置后端基于 Flask + SQLite3,前端 Vue3 + ElementUI-Plus,架构轻量、依赖少;同时支持 Docker 容器化一键部署,把环境配置与服务启动流程标准化。对于团队内部平台建设,先跑起来、再逐步扩指标** 是最现实的落地路线。
![图片[2]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143852732.png)
![图片[3]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143853894.png)
1. 个人/小团队训练看板:把实验“过程数据”沉淀下来
当你需要对比多次训练结果,光有最终指标不够,过程中的 loss 波动、训练时长、异常点更关键。GPU-Monitor 把这些过程信息可视化并留存,复现实验与复盘问题更省时间。
2. 共享服务器资源治理:减少抢卡、撞车与扯皮
多人共用一台/多台 GPU 服务器时,最怕资源被长期占用且无人认领。通过 GPU 利用率、显存占用、访问统计等信息的汇总展示,可以更快地定位异常占用与高频访问来源,形成“可追责、可优化”的资源使用规范。
3. 企业 AI 平台雏形:用低成本搭出训练可观测底座
对很多团队来说,上完整的企业级监控/审计平台成本高、周期长。GPU-Monitor 的轻量技术栈适合当作训练监控的起点:先覆盖最核心指标,再按业务扩展监控项与权限体系,逐步演进为内部 AI 平台的一部分。
![图片[4]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143854433.png)
1. 训练排障更快:把“猜问题”变成“看证据”
训练状态、日志、GPU 指标集中在一个面板里,遇到掉速、loss 异常、卡死等情况,可以先从指标与日志联动定位问题来源(资源争抢/IO 瓶颈/进程异常)。这会显著减少“人肉翻日志 + 反复重跑”的时间浪费。
2. 资源利用率更高:同样的卡,跑更多有效实验
通过实时 GPU 指标与筛选排序,你可以更快做资源编排(错峰、排队、迁移、回收),减少显存碎片化与无效占用。长期来看,同等硬件投入能产出更多有效实验结果,研发节奏更稳定。
3. 赚钱路径清晰:做成团队版/SaaS/私有化都能卖
把“训练监控 + 资源治理 + 访问审计 + 任务/实验管理”打包成产品,是很多企业的刚需。你可以基于开源版本做二次开发:对外提供私有化部署与运维服务,或做成团队版订阅(按 GPU 数/节点数/并发任务数计费),形成可持续的商业化收入。
![图片[5]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143855327.png)
1. AI 读日志:自然语言检索 + 异常根因推荐
在现有日志追踪基础上接入大模型,可支持“用一句话找问题”(例如“昨天晚上 loss 爆炸的那次训练发生了什么”),并对常见异常(OOM、IO 抖动、掉速、梯度异常)给出可能原因与处理建议,让排障从经验驱动变成知识驱动。
2. 智能资源调度:自动给出“下一张卡该跑谁”
结合 GPU 利用率、显存占用、历史训练配置与预计耗时,AI 可以生成排队与调度建议:哪些任务适合同机并行、哪些应避开高峰、什么时候回收空闲进程。对共享服务器而言,这能显著降低人为协调成本。
3. 训练过程预测:提前预警掉速与失败风险
把训练过程指标做成时序特征(吞吐、loss 变化、显存趋势、温度功耗等),可训练/微调预测模型,对“即将 OOM”“即将掉速”“可能发散”进行提前预警,并推荐减小 batch、启用梯度累积、切换混精等操作,把事故处理从事后变为事前。
![图片[6]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143856891.png)
![图片[7]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143856383.png)
总结
GCC GPU-Monitor用轻量技术栈把训练全过程的关键指标做成实时看板,覆盖训练进度、GPU 资源、日志追踪、公告与访问统计等能力,既适合个人/小团队快速搭建监控面板,也适合共享服务器做资源治理;进一步二次开发还能走向团队版与商业化交付,是“炼丹可观测化”的一个很实用的开源起点。
![图片[8]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143858515.png)
开源 GCC GPU-Monitor !完全开源!
这是个训练炼丹全流程监控系统,GPU 资源一眼看穿!
GCC GPU-Monitor这套开源训练监控系统,把训练状态、GPU 利用率/显存、训练日志、公告通知、IP 访问统计等关键指标做成实时看板,让“炼丹”从玄学变成可观测、可追踪、可复盘的工程流程。
源代码:
https://www.gitcc.com/qiyeapi/gcc-gpu-monitor
免费资源,完全开源!
我们整合了 50000+ 涵盖智能硬件、工业互联网、数字孪生、低空经济在内的技术文档和行业案例,一站式满足您的创新需求!
![图片[9]-千知](https://qianzhi-com.oss-cn-hangzhou.aliyuncs.com/wp-content/uploads/2026/06/20260610143859416.png)
点击关注,解锁你的财富密码!








暂无评论内容